Machine Learning
ENPH 353 Project: Self-driving and character recognition
This was a machine learning course that focused on an end-of-term competition, where teams of two developed machine learning models for self-driving and character recognition and competed in a simulated competition.
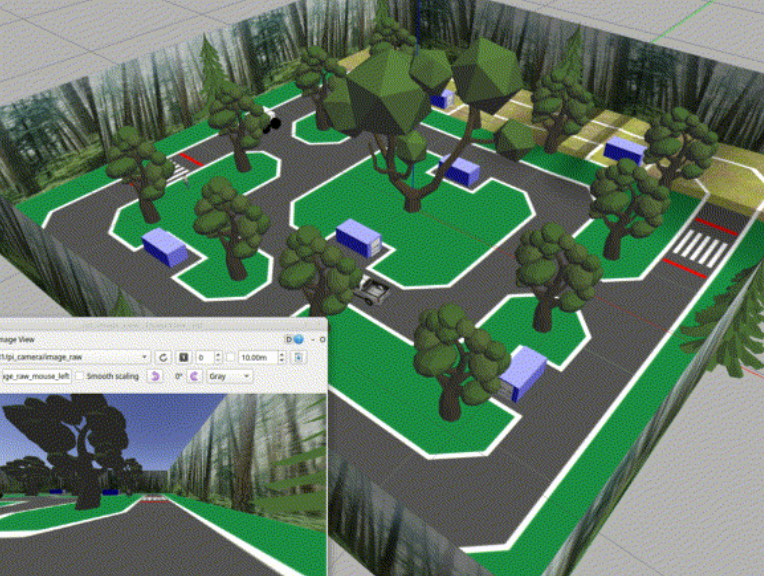
Competition environment. Bottom left is POV from car
A large challenge in this project was collecting data for the models. The driving model required creative ways to collect meaningful data, and the character recognition required a more traditional data augmentation approach.
Custom SAIL method: Data collection for driving model
As the driving controller utilized imitation learning, the model required “expert trajectories”, which is essentially a labelled dataset that is comprised of a given model input to a given model output. In this case, the labelled data was a given POV of the car (visual input) and the output was the driving command that was issued at that time, which was assumed to be the optimal controller choice, something my driving instructor would disagree with.
The key issue with collecting data is that when the model is nearly finished training with the dataset, and you need to collect a bit more data to ‘nudge’ the controller in the desired direction, there is already so much data that a few more does not make a large impact.
This was inspiration for my own custom method: SAIL (Selective Aggregation for Imitation Learning). This is the contribution for which I am most proud to this project. There is an existing method called DAgger (for example, in this paper on drone control), in which humans add, or aggregate to a dataset based on observed performance, to adjust the behavior of a model.
The main issue I found is that the new data is always littered with redundant data, or data that already agrees with the current behaviour. Thus by adding 50% redundant data and 50% new data, the effect of the new data is limited.
The solution that I came up with for this is by taking each new datapoint, running it through the current controller, and only adding it to the dataset if the outputs disagree with each other. This way, we include new expert labelled data without diluting the dataset with redundant data that the model already knows.
I am very proud of coming up with this method, as I have not seen it in the literature.
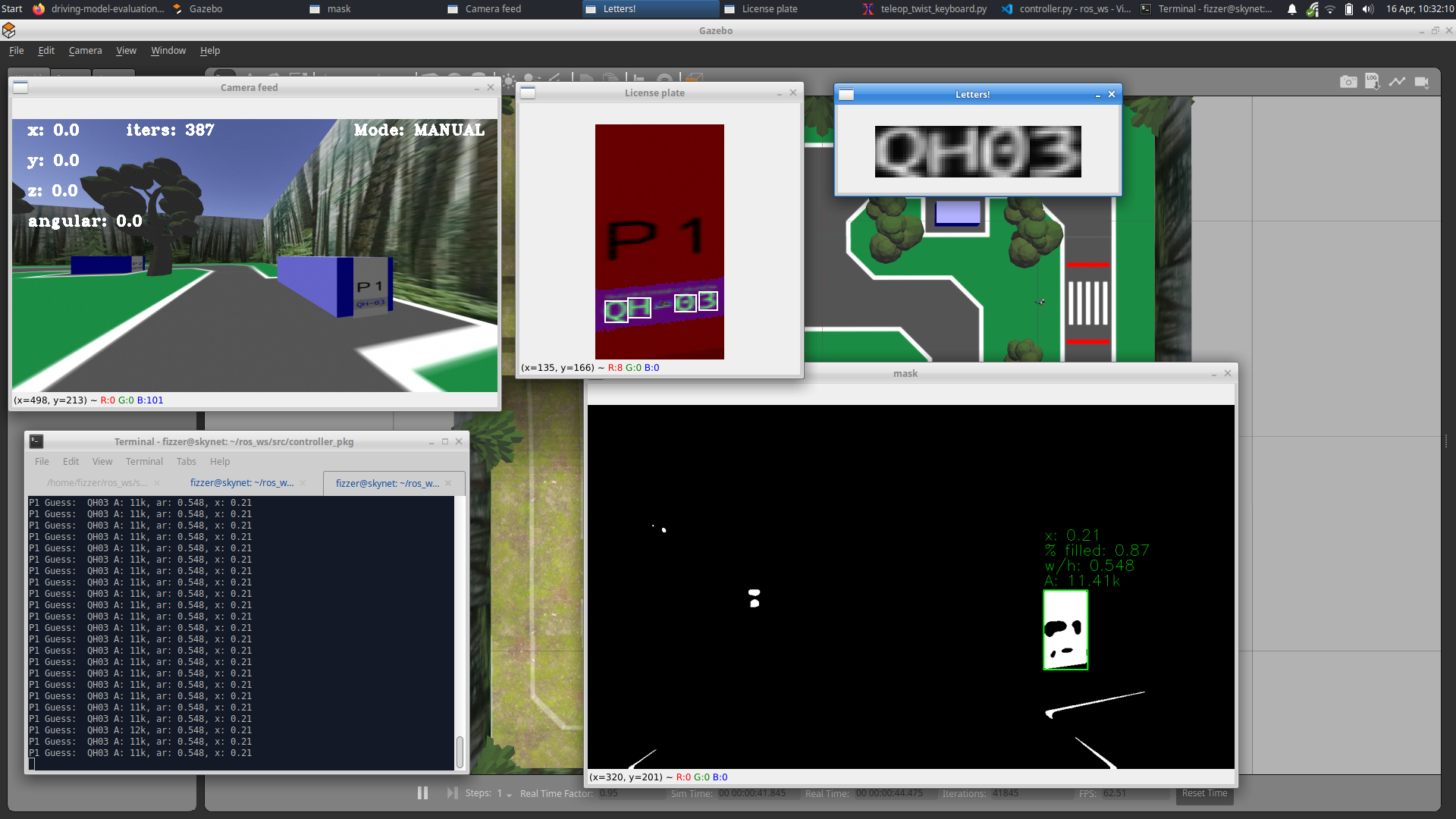
Various debugging tools used while training the models, and the computer vision methods to pre-process, including binary masking on a certain RGB range, filtering, and polygon detection.The pre-processing was done in OpenCV and later fed into a custom CNN
License-recognition model data collection: data pre-processing
The data collection for the image recognition model was much simpler. By finding the font that matched the existing license plates in simulation, I was able to augment the data using OpenCV to both replicate the existing perspective warps and angles that may exist in the simulation, and at the same time make the model more robust by training it on characters that were further distorted than what it will be given in-sim.

Output of character recognition model on custom-made pre-processed data.
This work demonstrates key steps in image preprocessing, such as binary masking, data augmentation, and the creation of a labeled dataset, along with the use of CNNs for character recognition. I was extremely proud of this work and thoroughly enjoyed it from start to finish.